
Shopify Plus is going through a considerable surge in popularity at the moment, with lots of household names choosing to migrate over to the SaaS eCommerce platform. I’m not an SEO and I don’t provide SEO services, however, I do work on a lot of replatforming projects and see SEO have a big input into the successfulness of those projects (and I used to be a lot more focused on SEO).

Shopify Plus has a number of SEO limitations, that often go unnoticed – so I thought I’d put together this guide to provide detail on these limitations and also the resolutions. Here are the core areas I’d suggest keeping an eye on.
Handling of filter pages
I thought I’d start with one of the most widely-known Shopify SEO issues, which is the handling of filter pages / layered navigation. Shopify’s filtering isn’t hugely effective and essentially the filters are only applying at a single level. The native setup here isn’t actually too bad, but it can be restrictive and if you have a lot of collection pages, you could still end up with a lot of dynamic pages being indexed.
Natively, Shopify all self-references the full URL in the canonical tag for the first set of filters and then adds the second level and anything beyond that with a “+” in the URL. Collection URLs with “+” used are blocked via the robots.txt file (which is the same for all Shopify stores), as can be seen below.
If you wanted to change the canonical URL setup so that filter pages point to the original collection page, you can simply edit the logic applied for the canonical URL for collections in the template files.
Handling of multiple storefronts
At present, Shopify Plus doesn’t have a multi-store architecture / solution, which means there’s no relationship with products on one store and a second store. This can have an impact on managing multiple stores (in that things like product IDs can be different and certain tasks will need to be repeated).
The impact that this has on SEO is largely around hreflang, as mapping the different URLs across different stores will be tricky, especially if the catalogs are different across stores.
This can still be done, you just need to create the logic in the templates and it’s not easy if you have different URL conventions or have localised product or category names for example.
Handling of redirects
Shopify Plus has various apps that make applying individual redirects very quick and easy, but these apps don’t apply for rule-based redirects. If you’re applying redirects via a .htaccess file, you’re able to use regular expressions to create logic for redirects (e.g. to carry parameters, redirect multiple categories, apply a blanket redirect for partial URL structure changes etc), this isn’t possible via Shopify.
In Shopify, you need to apply the rules in Excel really and then upload the redirects via a CSV file.
Here are the most commonly used apps for managing redirects:
- https://apps.shopify.com/easyredirects
- https://apps.shopify.com/transportr
- https://apps.shopify.com/redirect-bulk
I personally really like Transportr as it’s much faster in my experience (if you’re uploading large amounts of redirects) and it also supports various forms of logging. You can also filter 404 pages based on pageviews and integrate with Google Search Console.
JavaScript product grid
Due to the limitations in managing filtering in Shopify and Shopify Plus, lots of retailers opt to use a third party, which will almost definitely create a JavaScript-based solution. Products like Klevu and Algolia are examples of third party search and merchandising solutions that can improve merchandising and provide more complex filtering, but they use a JavaScript product grid which is essentially embedded onto the page.
A lot of people argue that Google (and some of the other search engines) are now a lot better at crawling JS-based content now, but I’d still say that the majority of technical SEOs would still not be comfortable relying on these search engines crawling a product grid that is being pulled in via JS.
One of the key benefits of using Shopify is how locked down the system is (providing benefits around scalability, stability, security etc), however, this means that technology partners aren’t able to extend the core functionality in places, as per this example.
There’s not really a way around this problem, aside from trying to create an html snapshot of the product grid on the page, which is how solutions like PreRender work – but again, this appears to be more complex with Shopify due to the restrictions around editing the code.
UPDATE:
BoostCommerce is a Shopify App that allows for proper multi-select filtering (powered by AJAX) but continues to use the native Shopify grid which is properly rendered via liquid. This is a really good option from an SEO perspective as there’s no reliance on JavaScript for the grid.
Inability to edit the robots.txt file
Shopify has a standard robots.txt file which cannot be edited, which again, does have some advantages. For larger stores, a lot of SEOs use the robots.txt file to control how search engines crawl the site – this isn’t possible in Shopify.
Shopify’s suggested alternative approach is to use noindex directives in the templates, which can support certain issues / resolutions – but this isn’t the same as using the robots.txt to control what’s actually being accessed by the crawler.
Oliver Mason (an experienced technical SEO Consultant) did come up with a clever fix for using the robots.txt by using / forcing a “+” in the URL, which would mean that the page is blocked via the wildcard rule referenced below, but it’s not a scalable / manageable solution, as he points out.
This is the default robots.txt in Shopify.
# we use Shopify as our ecommerce platform
User-agent: *
Disallow: /admin
Disallow: /cart
Disallow: /orders
Disallow: /checkout
Disallow: /1566146/checkouts
Disallow: /1566146/orders
Disallow: /carts
Disallow: /account
Disallow: /collections/*+*
Disallow: /collections/*%2B*
Disallow: /collections/*%2b*
Disallow: /blogs/*+*
Disallow: /blogs/*%2B*
Disallow: /blogs/*%2b*
Disallow: /*design_theme_id*
Disallow: /*preview_theme_id*
Disallow: /*preview_script_id*
Disallow: /discount/*
Disallow: /gift_cards/*
Disallow: /apple-app-site-association
Sitemap: https://www.gymshark.com/sitemap.xml
# Google adsbot ignores robots.txt unless specifically named!
User-agent: adsbot-google
Disallow: /checkout
Disallow: /carts
Disallow: /orders
Disallow: /1566146/checkouts
Disallow: /1566146/orders
Disallow: /discount/*
Disallow: /gift_cards/*
Disallow: /*design_theme_id*
Disallow: /*preview_theme_id*
Disallow: /*preview_script_id*
User-agent: Nutch
Disallow: /
User-agent: MJ12bot
Crawl-Delay: 10
User-agent: Pinterest
Crawl-delay: 1
Default hierarchical URLs
Shopify’s default setup will structure product links in the product grid to include the category path, so a link to a product within the mens > shoes > trainers category would look like:
Example.com/collections/mens-shoes-trainers/products/red-trainers-1
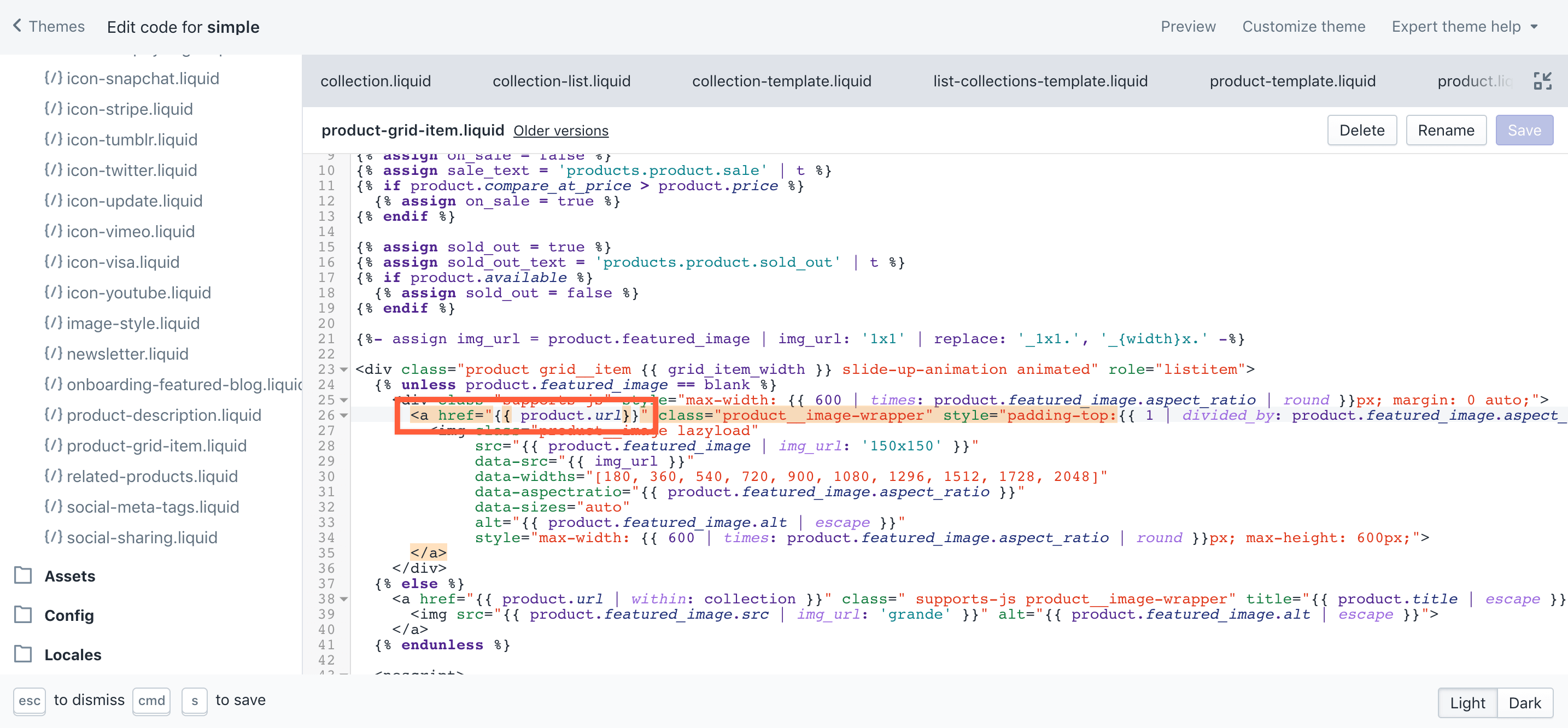
Although lots of people don’t do this, you can change this URL structure to force the top-level product to be referenced via all collection pages. The fix requires you to change the following in the template, as per this blog post I wrote a couple of months ago.
Collection hierarchy
Another challenge from an SEO management perspective is that Shopify doesn’t currently have any concept of hierarchy in collections, making things like achieving a best practice URL structure and internal linking logic complex. You can manually include forward slashes to create a parent <> child-like sub directory structure, but it needs to be managed manually and there’s no underlying logic there.
This isn’t something that’s really possible to overcome, but it’s something that’s likely to be improved over time. In other platforms, there are parent / child relationships with categories, making things easier for admin users to make changes at a global parent level.
One thing you can do to improve the internal linking side of things is to use menus (which are then outputted within the templates) or use a URL convention that could allow for a parent <> child-like association – I’ve done this in the past to allow for links to related or children categories within content blocks.
—
This post was updated in December 2018, having been originally published in July 2018.
If there are any points you think I’ve missed or anything you’d like to add, please feel free to add them in the comments below.

One Response
Can you give some insight as to why Shopify disallows /search and /gift_card in robots.txt?
Google Search Console is giving a coverage issue detected for /search every day. “Coverage may be negatively affected in Google Search results. We encourage you to fix this issue. ”
Thanks