
I’ve worked on countless Magento websites that have unknowingly faced duplicate content issues, which have either held them back or lead to panda-related issues. These issues vary in terms of impact (primarily because of the volume of pages) but they’re all fairly easy to resolve, so I’d suggest reading through the post and actioning the recommendations alongside each one. If you have any questions about any of the issues mentioned below, feel free to drop me an email ([email protected]) – I’ve got experience of resolving all of them and have an extension to help reduce the overhead in terms of development work.
Blanket delivery / service content
Most ecommerce websites have blanket delivery or service-based content on product pages, which is featured on every page of the website, which isn’t too much of an issue in principle but can become an issue if you don’t have very much product copy. I’d suggest avoiding this if possible, but if you do opt to publish this kind of content, I’d suggest trying to ensure that it doesn’t account for more than 15-20% of the total content featured on the product pages.
Product page templates are very important and the more unique content you can build into the design of the page, the better.
Layered navigation pages
Layered / faceted navigation is easily the most common duplicate content issue for Magento websites and it’s usually the most troublesome as well. Here are some examples of common layered navigation URLs:
http://www.shopfortots.com.au/shopby/bebe_clothing-kinetic_sand-alphabet_soup.html (this example also has multiple filters applied)
http://www.chopard.com/watches?gender=218 (the conventional Magento query string-based filter)
These are two examples of dynamic filter pages, which can cause all kinds of issues, due to the level of volumes that can be generated. Multi-select layered navigation can be even worse and can cause issues with crawl budget, as well as the obvious over-indexation implications.
There are various different resolutions for this issue, with the canonical tag probably representing the best one – although it’s fairly temperamental and doesn’t always prevent the pages from indexed. I tend to use noindex, follow meta robots tags in most cases, although if it’s a very big website, I’ll use the robots.txt. I recently worked on a US-based fashion retail website who used multi-select in their faceted navigation, which created thousands and thousands of dynamic variations of their category pages. In this scenario, purely because of the volume of pages, I recommended using the robots.txt, in order to prevent the level of pages impacting their crawl budget.
Other resolutions could be the parameter handling in Google Webmaster Tools, which I’ve not had much success with in the past (but some people have) or using a hash in the URL.
Here’s an example of this issue from the Tissot website:
There’s more information on best practice with layered navigation in Magento in this guide to Magento SEO.
Pagination pages
Pagination is one of the oldest duplicate content issues and is caused by paginated versions of category pages. A few years ago, Google announced the rel next and prev tags, which are designed to indicate when a paginated page is a variant of the main category page. I’d suggest using the rel next and prev tags alongside noindex, follow meta robots tags, which will prevent the pages from being indexed.
Rel next can be implemented in the <head> section or on the pagination link itself. The first page should only contain the rel=next link and the second (and others) should then reference the previous and next page.
Here’s an example of rel next and prev being used in the <head>:
<link rel=”next” href=”http://www.example.com/shop/mens?p=5″>
<link rel=”prev” href=”http://www.example.com/shop/mens?p=3″ />
Here’s an example of it being used in the link attribute:
<link rel=”next” href=”http://www.example.com/shop/mens?p=3″ />
It’s worth noting that rel next and prev tags aren’t actually directives, they are designed to illustrate that the page is a paginated version of the original page, but they’re not necessarily going to change the way Google treats the page.
Session ID pages
Session ID pages can be very annoying and are usually a result of an implementation requiring a user to go from one sub-domain or http protocol to another. Session IDs (which are appended to URLs via SID=x) are generated to track the user’s session, but there’s no limit to the number of URLs that can be generated as a result.
If this is an issue for you, I’d suggest blocking them via the robots.txt file. I don’t usually like using the robots.txt file unnecessarily, but because of the potential volume of pages, other alternatives could take up a lot of your crawl budget.
Review pages
If you’re using Magento’s out of the box review functionality, then you’re likely to have a duplicate content issue as a result. In addition to the review content being published on the associated product page, Magento also creates a separate page for each product, which also has the same review content as the product pages. I would suggest preventing search engines from accessing these pages, either via the robots.txt or meta robots rules, as they add no value to the user (it’s fairly difficult to navigate back to the original product and it’s a strange user experience), plus they can add a lot of duplicate content to your Magento store.
Feed-related issues
For me, feeds represent the biggest duplicate content threat to online retailers – as in most cases, you’re allowing other websites to publish the same content that is being featured on your website. I’ve seen plenty of panda issues result from feeds, which has lead to significant reductions in revenue for retailers who didn’t realise they were doing anything wrong.
I’d suggest, if you’re going to work with affiliates, resellers, Amazon / eBay stores etc, you should be creating a second set of content, which can be supplied via a separate feed. I know this is a very big overhead in terms of resource, allowing other websites to publish your content is a huge risk for your organic channel.
Sort / order pages
Sort / order pages are designed to aid the user experience, by allowing the user to change the order of how products on category pages are displayed. The problem is that when you apply the filter, a query string is appended to the URL (similarly to the layered navigation issue mentioned earlier) – this creates a duplicate version of the original category page. You could easily have thousands of these for a mid-level Magento website.
The obvious solution for this is to use the canonical tag, which I would recommend if you’re launching a new website. If you then find the pages are being indexed anyway, I’d suggest using meta robots tags or the robots.txt file.
If you already have a lot of these URLs in the index, I’d suggest using the latter two recommendations as these will help you to meet the requirements for submitting a removal request in Google Webmaster Tools.
Using the same content on slightly different versions of products
This is very common and it’s an annoying issue to resolve, as it usually requires the merchant / store to re-write product content. If you have a specific type of tyre for example, which has slightly different variants (and you’ve not used configurable products), then most people would’ve used the same content and adapted slightly, but it’d still be largely the same.
In this scenario (dependant on the volume), you would have a lot of very similar pages, which isn’t good. You can choose to either canonicalise to a primary version and ensuring that your navigation allows the user to find the version they want (which would mean that you’d be less likely to rank for the specific keyword) or you could re-write the copy for each variant.
If you’re starting from scratch, I’d probably use configurable products, as it’s easier to maintain and you can simply optimise for each size – however, if you’ve got this problem, it depends on the level of organic landing traffic each variant is getting.
You could also create configurable versions and redirect the individuals, but this is likely to take a long time.
Using category path in URL
In more recent versions of Magento, the URLs are set to automatically use hierarchical (including category path) URLs and then canonicalise to the top-level equivalent – here’s an example:
If you have all of the following:
www.example.com/clothing/shirts/red/example-product-name
www.example.com/sale/example-product-name
www.example.com/mens/shirts/example-product-name
Each of these would canonicalise to:
www.example.com/example-product-name – this would be the page that ranks in Google and it would be treated as the primary.
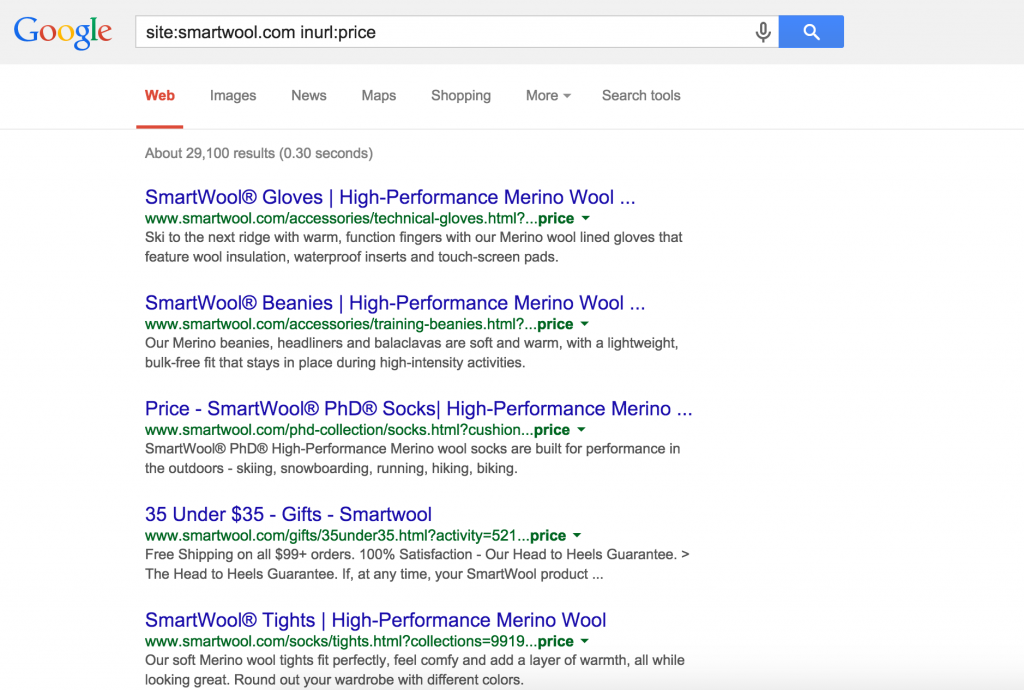
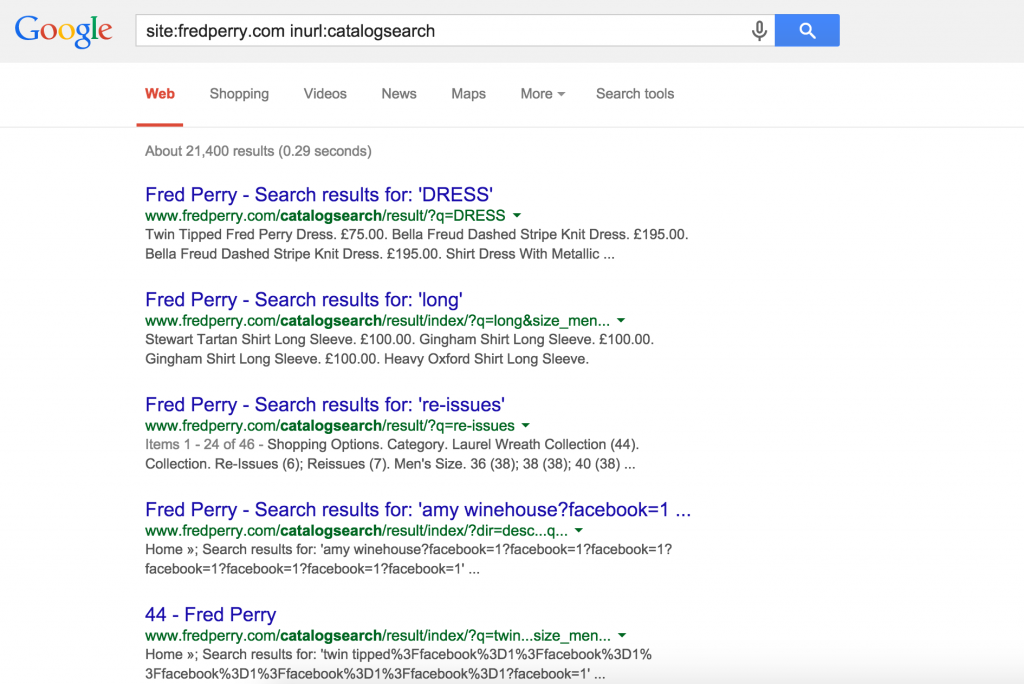
Search pages
Another very common duplicate content issue for Magento websites is that the catalogsearch pages are indexed – which can result in thousands of search pages being indexed by Google and other search engines. I’d suggest blocking these pages via your robots.txt file, as there could be quite a lot of them. If you have lots of these pages in the index, once you’ve disallowed the directory in the robots.txt file, you can simply submit a directory-level removal request for /catalogsearch/.
Here’s a screenshot from the Fred Perry website:
Product descriptions on category pages
A lot of retailers, especially those with less products, opt to display brief descriptions for each products on category pages – this is commonly pulled from the product page, making it duplicate content. In a lot of cases this results in the majority of your category page copy being duplicate content. This is a bigger issue when you have duplicate content on product pages, as this would leave you with very few pages with unique content, which could lead to a panda penalty.
I’d suggest either not doing this or creating new content for the category pages.
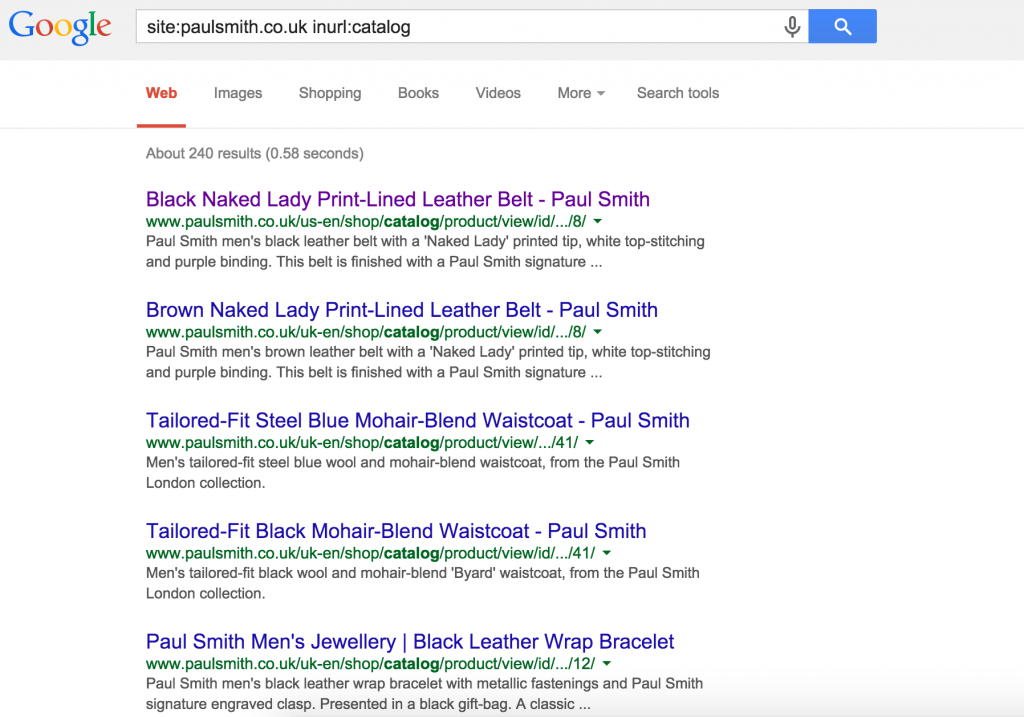
/catalog/ URLs
In earlier versions of Magento, the URLs were in the format below:
http://www.paulsmith.co.uk/us-en/shop/catalog/product/view/id/100310/s/men-s-black-naked-lady-print-lined-leather-belt/category/8/
These URLs often still exist due to issues with the rewrites in Magento and they’re often indexed by search engines. Here’s an example from the Paul Smith website:
www vs non-www
One of the more basic duplicate content issues with Magento websites (and websites in general) is having both the www and the non-www render the same page for each URL. This is really easy to fix, you simply need to add a rewrite rule in your .htaccess file and ensure that each URL redirects to the equivalent on your preferred prefix.
Staging websites
Staging websites can be a complete nightmare and it’s very common for merchants and development agencies to leave them indexable. I’d suggest putting all staging environments behind a password, as this will prevent search engines from accessing the content. You could also use a robots.txt file or meta robots tags, which will also allow you achieve the same end goal.
If you’re doing this, the key thing is that you avoid pushing any of these options onto the live site when deploying changes. This is something I’ve seen time and time again and it can be very annoying.
—
If you have any questions about Magento SEO or would like to discuss an audit or consulting project, please feel free to email me on [email protected] or fill out this form.
